Datenbanken & Informationssysteme
Klassischer Klausuraufbau:
- ER-Diagramm zeichnen
- Relationales Datenbankschema aus ER-Diagramm
- Relationale Algebra, Kalküle
- SQL Queries formulieren zu gegebenen Table
- Funktionale Abhängigkeiten, Normalform
- Synthese, Dekomposition
- Serialisierbarkeit, Nebenläufigkeit, Transaktionsmanagment
- -Baum, B-Baum
- XML
- RDF, SPARQL (XPath, XQuery)
Einführung
Ein Datenbanksystem besteht aus:
- Datenbank-Managementsystem (DBMS): Verwaltung der Datenbank; Schnittstelle
- Datenbank (DB): Sammlung aller Daten/Schemata
Big Data Problem: Erfassung, Verarbeitung und Analyse von Daten erfordert immer häufiger effiziente Datenbanksysteme
Entity-Relationship-Modell
Datenbankentwurf
Bestimmung der Struktur und des allgemeinen Aufbaus der Datenbank.
Anforderungsanalyse Entwurf Implementierung Validierung Betrieb ( Evolution)
ER-Diagramm
Entity-Typ (Objekt):
Entity-Set (Objektmenge): Menge von konkreten Instanzen des Entity-Typ
Attribute:
Ein Attribut beschreibt die Eigenschaften einer zugehörigen Entity.
Schlüssel:
Einzigartig für eine Instanz.
Ein Attribut kann aus mehreren Attributen bestehen.
Mehrwertige Attribute:
Relationship:
Rekursive Beziehung:
isA Beziehung: partiell:
- Die erbenden Entities decken nur ein Teil der ursprünglichen Entity ab
- Die erbenden Entities spezialisieren alle ursprünglichen Entities
Konzeptueller Entwurf
Relationale Datenmodell
Relationen: von Domänen z.B. oder
Tupel:
Schlüssel: Teilmenge S der Attribute, sodass für Tupel gilt:
Im geordneten Relationenschema spielt ist . Im ungeordneten Relationenschema spielt die Reihenfolge im Tupel keine Rolle.
ER-Diagramm zum relationalen Modell
- Entity-Typ Tabelle/Relation: Student(, Name, Status) - Zusammengesetzte Attribute werden zu einzelnen Attributen
-
n:m Beziehungen Relationen für Relation und Entities:
- Relationen: Entity1(); Entity2(); Relationship()
- Interrelationale Abhängigkeiten: Relationship[Key1] Entity1[Key1]; Relationship[Key2] Entity2[Key2]
- Die "Relationship" bekommt Key1 und Key2 als Fremdschlüssel
-
1:n Beziehungen
- Relationen: Entity1(, Attr1); Entity2(, Entity1Key1Relation)
- Interrelationale Abhängigkeiten: Entity2[Entity1Key1Relation] Entity1[Key1]
- Vorteil: Keine extra Relation für Relation
- Nachteil: Für Entities die nicht in Beziehung stehen ist Entity1Key1Relation leer
-
1:1 Beziehungen
- Verschmelzen von 2 Entities zu einer Relation
- Relationen: Entity1(, Attr1, Key2 Attr2)
-
Rekursive Beziehungen
- Relationen: Relation(, )
- Interrelationale Abhängigkeiten: Relation[Vorgänger] Entity[Key]; Relation[Nachfolger] Entity[Key]
-
isA Beziehungen
- Relationen: Key der Parent-Entity auch für Children-Entity
- Interrelationale Abhängigkeiten: Children[Key] Parent[Key] und Schnittmenge zwischen Children-Relationen ist die leere Menge
-
Mehrwertiges Attribut:
- Aus dem mehwertigen Attribut wird eine Relation
- Relationen: Entity(, Attr); Mehrwertig(, )
- Interrelationale Abhängigkeiten: Mehrwertig[Key] Student[Matrkielnummer]
Relationale Algebra
Relationen als Wertebereich. Somit sind R,S Mengen von Tupeln
Grundoperationen
-
Vereinigung:
- Vereinigt und löscht Duplikate
-
Differenz:
- Alle Tupel aus R, welche nicht in S sind
-
Kartesisches Produkt:
- Jedes Tupel aus R verknüpft mit jedem Tupel aus S
-
Selektion:
- Selektiert alle Tupel, welche dem boolschen Ausdruck F entsprechen
-
Projektion:
- Gibt nur die Attribute (Spalten) zurück
-
Umbenennung: oder
- Bennent Relation R in R' um
- Bennent Attribut A in A' um für eine Relation R
Alle Grundoperationen sind induktiv definiert, sodass eine Relation auch durch eine gültige Operation auf einer Relation ersetzt werden kann.
Weitere Operationen
- Durchschnitt:
-
Natürlicher Verbund (natural join):
- Zusammenfügen von Relationen in Abhängigkeit von übereinstimmenden Attributen
- Funktioniert nur bei gleichen Attributnamen
- kommutativ und assoziativ
-
Theta-Join:
- Nur passende Attribute des Kreuzprodukts
- Doppelte Attribute werden nicht aussortiert!
- Weitere join operationen

Relationale Kalkül
Deklarative Sprache (im Gegensatz zur prozeduralen Sprache der relationalen Algebra)
Tupelkalkül
Alle Tupel t die die Formel erfüllen
z.B.
Domänenkalkül
Ein Ausdruck mit k Bereichsvariablen:
z.B.
SQL
Structured Query Language ist eine Mischung aus relationaler Algebra und des relationalen Kalküls. SQL ist eine deklarative Datenbankanfragensprache.
CREATE TABLE Cars (
SerialNumber INTEGER NOT NULL,
CarName VARCHAR (50),
OwnerId VARCHAR (50) REFERENCES Owner(OwnerId)
PRIMARY KEY (SerialNumber)
);
ALTER TABLE Cars
ADD LicencePlate VARCHAR (50);
ALTER TABLE CARs
DROP COLUMN CarName;
CREATE UNIQUE INDEX CarIndex
ON Cars (SerialNumber);
DROP INDEX CarIndex;
// DROP TABLE;Views
CREATE VIEW OwnedCars AS
SELECT * FROM Cars WHERE OwnerId IS NOT NULL;Data Manipulation Language
Data Manipulation Language (DML) von SQL
SELECT * // Projektion
FROM Cars // Kreuzprodukt
WHERE CarName LIKE '%BMW%' // SelektionSELECT DISTINCT gibt nur einmalig eine Zeile zurück. Duplikate werden ignoriert.
Aggregatfunktionen
SELECT [COUNT, MIN, MAX, SUM, AVG] ([Distinct] <Attribut>)
FROM ... WHERE ...COUNT: Anzahl der Zeilen zu gegebener Querry
SUM : Summe der Werte eines Attributs
Gruppieren und Sortieren
SELECT * FROM ...
GROUP BY <Liste von Attributen>
ORDER BY <Liste von Attributen> ASC/DESCJoin
// Theat-Join
SELECT * FROM Cars ...
JOIN ... ON <Bedingung für Attribute>Es exestieren noch LEFT (OUTER) JOIN, RIGHT (OUTER) JOIN, FULL (OUTER) JOIN, welche analog zu JOIN verwendet werden können. Die funktionsweise lässt sich an der Grafik gut veranschaulichen.
Änderungen
INSERT INTO Cars (CarName, OwnerId)
VALUES ('BMW',1)
DELETE FROM Cars WHERE ...
UPDATE Cars
SET Price = Price + 200
WHERE CarName = %'BMW'%Relationale Anfragebearbeitung
Günstigsten Auswertungsplan ermitteln.
SQL zu relationaler Algebra (kanonisch)
- Bilde das kartesische Produkt der Relationen
- Führe Selektionen mit den einzelnen Bedingungen durch
- Projeziere auf erforderliche Attribute
Beispiel:
SELECT VName, NName
FROM Studenten AS S, Professoren AS P
WHERE S.NName = P.NName
AND S.Alter < P.Alter - 20Wird zu:
regelbasierte Anfragenoptimierung
Restrukturierungsalgorithmus
- Aufbrechen der Selektion
- Verschieben der Selektion nach unten
- Kreuzprodukte und Selektionen zu Joins zusammenfassen
- Einfügen und verschieben von Projektionen
- (Zusammenfassen von Selektionen)
Die Idee ist Selektionen möglichst früh durchzuführen und somit eine Performance-Verbesserung zu erreichen.
Indexstrukturen
Prozesse sollen nebenläufig auf Daten arbeiten können. Für sowas verwendet man Festplatten als Sekundärspeicher. Die Daten werden in Blöcken gespeichert.
eindimensionale Daten
Mehrwege-Bäume: Alle Knoten haben viele Nachfolger ud M viele Schlüssel.
B-Baum: M+1 Mehrwege Suchbaum für eine gerade Zahl M.
- Suchen: Binär vergleichen auf dem jeweiligen Knoten; Suche rekursiv in den Teilbaum. Benötigte Vergleiche:
-
Einfügen
- Passendes Blatt für Objekt suchen
- Wenn hierdurch das Blatt überläuft, spalte es auf
-
Löschen
- Bei einem Blatt: Lösche Schlüssel aus dem Blatt
- Bei inneren Knoten: Suche größten Schlüssel links vom zu löschenden Schlüssel. Ersetze den zulöschenden durch den gefundenen Knoten. Lösche den zu löschenden Knoten
- Bei der Wurzel: So wie bei den anderen beiden, nur darf die Wurzel weniger als M/2 Schlüssel haben
Einfügen:
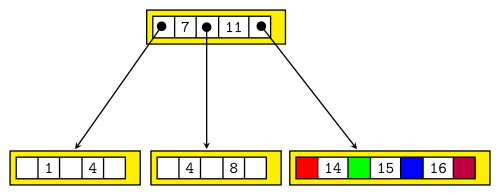
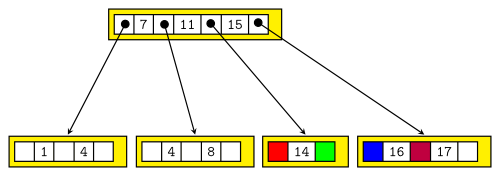
-Baum: B-Baum Variante mit zwei Knotentypen
- Blätter enthalten Schlüssel mit Datensätzen oder Verweisen auf Datensätzen
-Baum speichert Schlüssel ohne Daten. Dadurch ist der -Baum meist breiter und weniger hoch als ein B-Baum.
mehrdimensionale Daten
Invertierte Listen
Quadtree
R-Baum (Rectangel-Baum)
Relationale Entwurfstheorie
Funktionale Abhängigkeiten
Sei eine Attributmenge und ein Relationenschema. .
funktional abhängig von :
intrarelationale Abhängigkeit: : 1, falls in R gilt, sonst 0
voll funktional abhängig: Es gilt , aber für alle .
Schlüsselkandidat: Attributmenge ist ein Schlüsselkandidat, wenn voll funktional abhängig von ist
Primärschlüssel: Einer der Schlüsselkandidaten
R erfüllt funktionale Abhängigkeiten , wenn für Tupel p,q gilt und